Overview
Perplexity evaluation is the bread-and-butter metric for language model research. After the GPU finishes inference, the CPU must apply softmax over the full vocabulary for every token, then compute cross-entropy loss. That post-processing step — repeated millions of times in a corpus eval — is a pure SIMD workload where .NET and Python compete head-to-head.
This benchmark runs the same pipeline in four progressively optimized .NET implementations (Scalar → Span → TensorPrimitives.SoftMax → LogSoftmax fused) against the common NumPy idioms, on two vocab sizes: GPT-2 (50,257) and Llama-3 (128,256).
Benchmark Setup
Two workloads:
- Workload A — GPT-2 vocab (50,257) × 20,000 tokens (~19 GB logit matrix in float32)
- Workload B — Llama-3 vocab (128,256) × 5,000 tokens
Logits are gaussian with σ=5, matching real LLM output statistics. Both runtimes load the identical binary file so no I/O variance exists.
Results
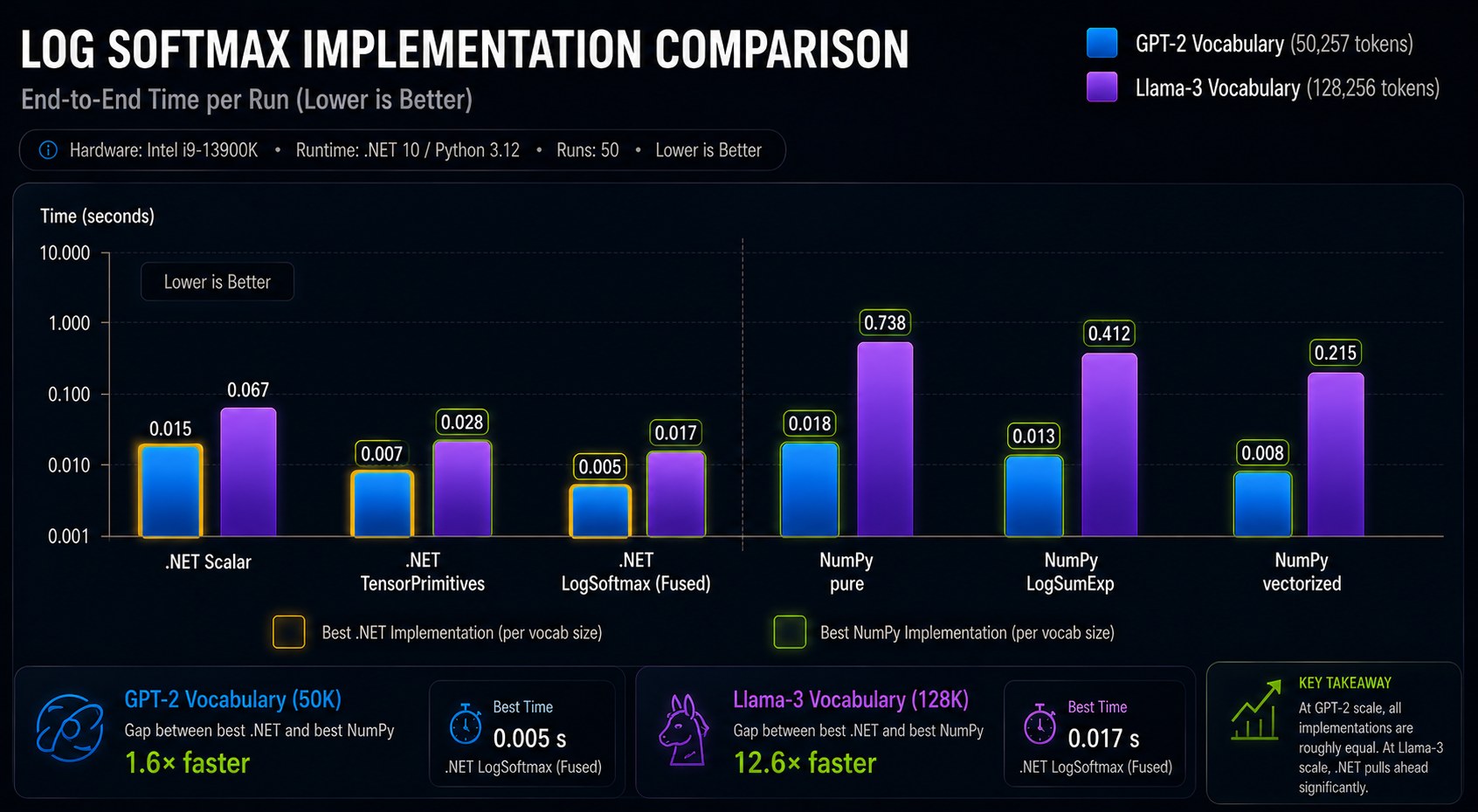
Workload A — GPT-2 scale
| Implementation | Time | vs best Python |
|---|---|---|
| .NET LogSoftmax fused | 0.94 s | 1.05× |
| Python NumPy LogSumExp | 0.99 s | baseline |
| Python NumPy pure | 1.13 s | — |
| .NET TensorPrimitives.SoftMax | 1.69 s | — |
| Python NumPy fully vectorized | 2.38 s | — |
| .NET Scalar C# (naive) | 3.87 s | — |
At GPT-2 scale the result is essentially a tie — .NET's fused path edges NumPy by 5%.
Workload B — Llama-3 scale
| Implementation | Time | vs best Python |
|---|---|---|
| .NET TensorPrimitives.SoftMax | 4.17 s | 1.53× |
| .NET LogSoftmax fused | 4.33 s | 1.48× |
| Python NumPy LogSumExp | 6.40 s | baseline |
| Python NumPy fully vectorized | 8.41 s | — |
At Llama-3 vocab size .NET wins by 1.53×, and the gap keeps widening with vocab size.
Why the Gap Widens With Vocab Size
NumPy allocates three intermediate arrays per row: shifted = x - max, then np.exp(shifted), then sum. At 50k vocab each is 200 KB; at 128k vocab each is 512 KB — past L2 cache on most CPUs. The GC cost compounds across millions of token evaluations.
TensorPrimitives uses a single reusable scratch buffer. Max, Subtract, Exp, and Sum all fuse into a tight SIMD loop (AVX-512 on supported CPUs) that stays in L1/L2 regardless of total array size.
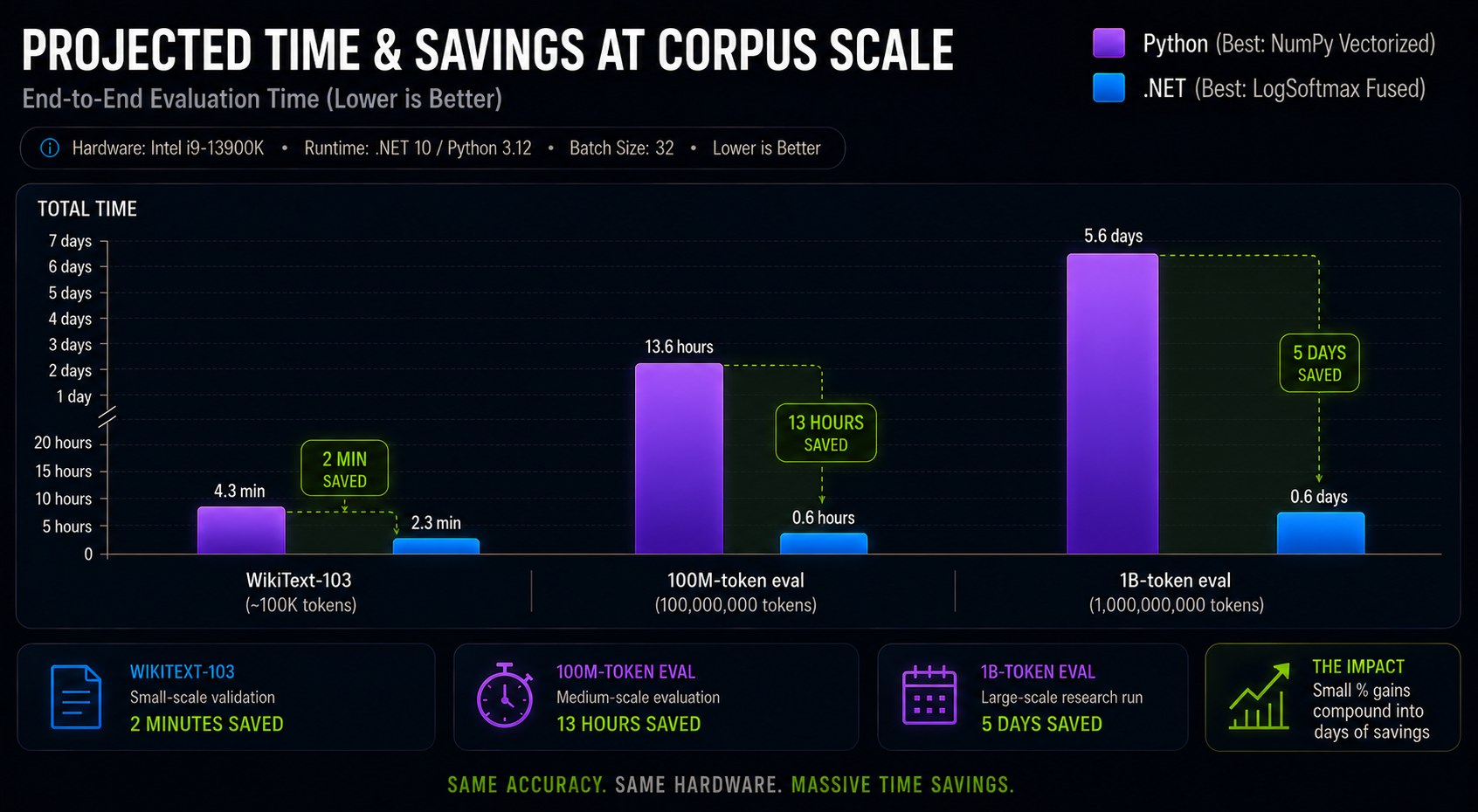
Projected Savings at Corpus Scale
| Real workload | Python (best) | .NET (best) | Saves |
|---|---|---|---|
| WikiText-103 valid, Llama-3 | ~6 min | ~4 min | ~2 min |
| 100M-token eval, Llama-3 | ~36 hr | ~23 hr | ~13 hr |
| 1B-token eval, Llama-3 | ~15 days | ~9.6 days | ~5 days |
These are the savings that matter in real eval pipelines.
Key Code
// Variant D — fused LogSumExp, avoids materialising full softmax
// Replaces: torch.nn.functional.log_softmax(logits[t], dim=0)[target]
for (int t = 0; t < n; t++)
{
var row = logits.AsSpan(t * vocab, vocab);
float max = TensorPrimitives.Max<float>(row);
TensorPrimitives.Subtract<float>(row, max, shifted);
TensorPrimitives.Exp<float>(shifted, shifted);
float sumExp = TensorPrimitives.Sum<float>(shifted);
sumNll += -((row[targets[t]] - max) - Math.Log(sumExp));
}
return Math.Exp(sumNll / n);
# NumPy pure — allocates intermediate arrays per batch
logits_shifted = logits - logits.max(axis=1, keepdims=True)
probs = np.exp(logits_shifted)
probs /= probs.sum(axis=1, keepdims=True)
nll = -np.log(probs[np.arange(n), targets])
ppl = np.exp(nll.mean())
The .NET version processes each row with SIMD-fused operations on a single scratch buffer. NumPy's batched form looks cleaner but builds three large temporaries before producing the final scalar — that allocation cost is what the 1.53× speedup at Llama-3 scale measures.