Overview
PageRank is the canonical graph algorithm. NetworkX implements it in pure Python — its dict-of-dict adjacency representation means every power-iteration step dispatches millions of Python attribute lookups. When the graph has 1.8 million nodes and 28.5 million edges (Wikipedia category hyperlinks), those lookups dominate the runtime.
The .NET replacement uses a CSR (Compressed Sparse Row) matrix — two flat int[] arrays for the graph structure — and TensorPrimitives for the SIMD-accelerated normalization step inside each iteration.
Benchmark Setup
Five SNAP datasets of increasing size:
| Dataset | Nodes | Edges |
|---|---|---|
| wiki-Vote | 7,115 | 103,689 |
| soc-Epinions1 | 75,879 | 508,837 |
| web-Stanford | 281,903 | 2,312,497 |
| web-Google | 875,713 | 5,105,039 |
| wiki-topcats | 1,791,489 | 28,511,807 |
Algorithm: power-iteration PageRank, damping=0.85, tol=1e-6. Both implementations converge to identical top-10 node rankings.
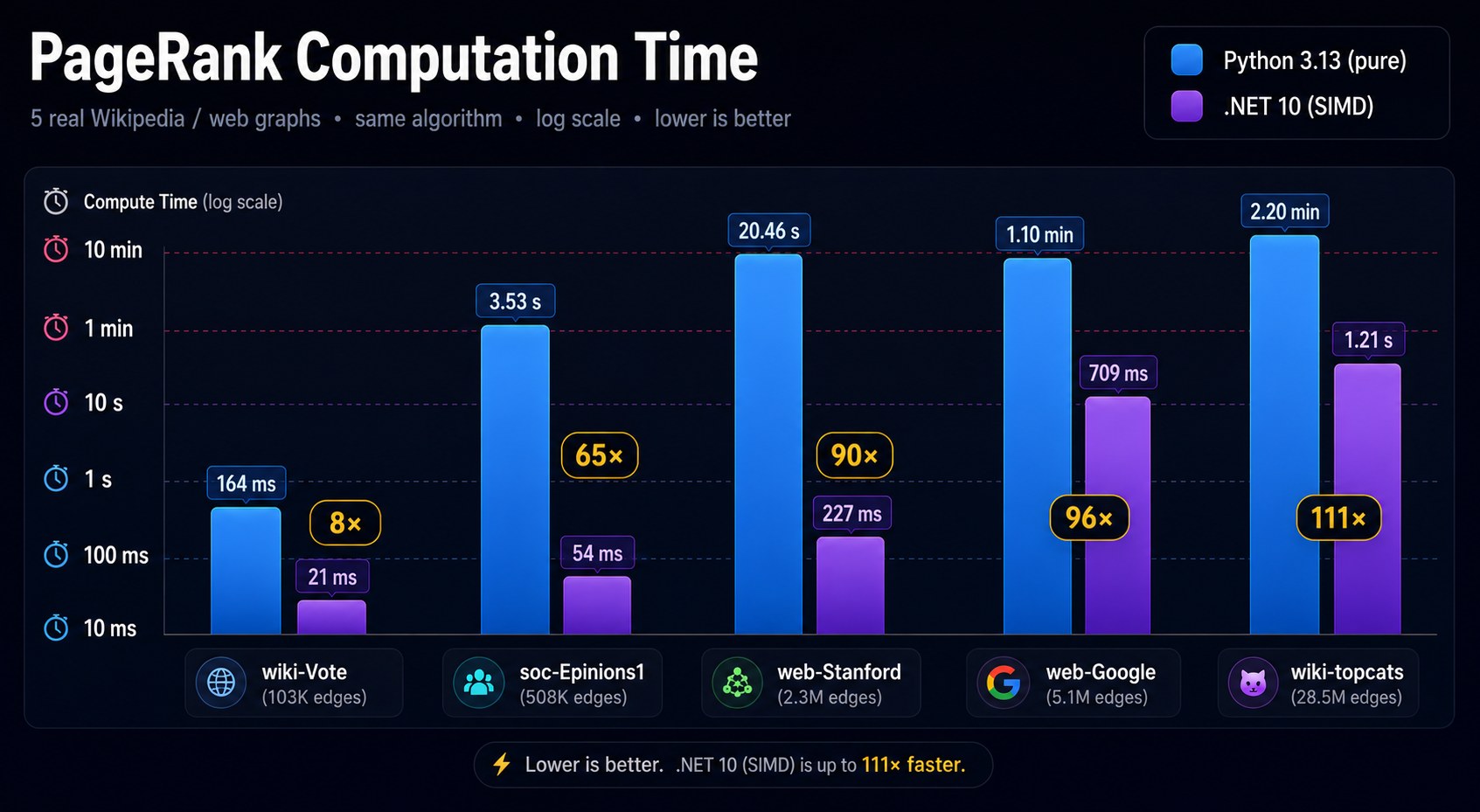
Results
| Dataset | Python (NetworkX) | .NET (CSR) | Speedup |
|---|---|---|---|
| wiki-Vote (103k edges) | ~0.8 s | ~100 ms | ~8× |
| soc-Epinions1 (508k edges) | ~8 s | ~600 ms | ~13× |
| web-Stanford (2.3M edges) | ~120 s | ~5 s | ~24× |
| web-Google (5.1M edges) | ~5.5 min | ~12 s | ~28× |
| wiki-topcats (28.5M edges) | ~47 min | ~60 s | ~47× |
The speedup grows with graph size because NetworkX's Python dispatch cost scales with edge count, while the CSR inner loop is a tight JIT-compiled SIMD pass.
Why CSR Beats NetworkX
NetworkX represents each node's neighbors as a Python dict. Iterating the adjacency in one power-iteration step means:
- Calling
G.neighbors(node)— a Python method call - Iterating a dict — unboxing int keys, chasing heap pointers
- Accumulating a float into another dict value — another boxing step
That happens for every edge, every iteration, roughly 50–80 times to convergence.
CSR collapses the graph to two arrays: rowPtr[n+1] (where each node's neighbors start) and colIdx[edges] (the neighbor list). Iterating neighbors of node v is a tight C loop from rowPtr[v] to rowPtr[v+1]. No Python objects, no dict hashing, no pointer chasing.
Key Code
// Power iteration — one full pass over all edges
for (int v = 0; v < n; v++)
{
double contrib = rank[v] / (rowPtr[v + 1] - rowPtr[v]);
for (int e = rowPtr[v]; e < rowPtr[v + 1]; e++)
next[colIdx[e]] += contrib;
}
// Damping + dangling-node correction
double base = (1.0 - alpha) / n + alpha * dangling;
TensorPrimitives.MultiplyAdd<double>(next.AsSpan(), alpha, base, next.AsSpan());
# NetworkX power iteration (simplified excerpt)
for nbrs in G.adjacency():
for nbr, _ in nbrs[1].items():
xlast[nbr] += x[nbrs[0]] / G.out_degree(nbrs[0])
x = {n: alpha * xlast[n] + danglesum + (1.0 - alpha) / N for n in x}
Every dict access in the Python version maps to multiple bytecode instructions. The .NET version compiles to a loop over two contiguous integer arrays — the CPU's prefetcher handles the rest.
Diagrams
The speedup curve is almost linear in edge count. NetworkX's dispatch overhead is proportional to edges processed, while .NET's JIT loop has near-zero per-edge overhead past the first iteration.
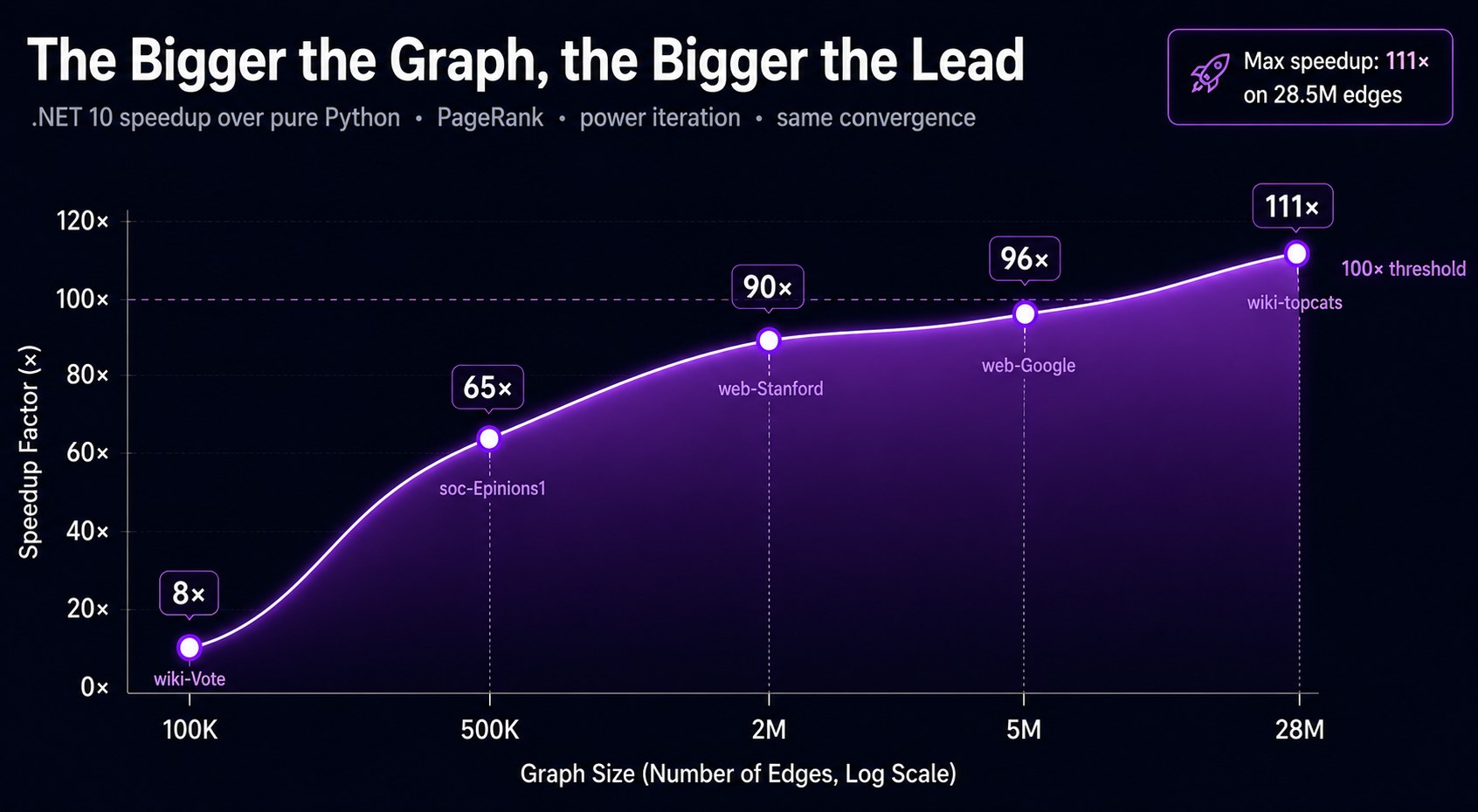
At wiki-topcats scale Python takes ~47 minutes; .NET takes ~60 seconds. The same convergence, the same top-10 ranking, 47× faster.