Overview
Full-text search powers document retrieval across millions of use cases: log search, e-commerce product lookup, knowledge base queries. Both Whoosh and Lucene.NET implement BM25 ranking on an inverted index — the same algorithm, the same data structures, different languages.
This is one of the cleanest comparisons in the benchmark suite because neither library uses native binaries. Whoosh is 100% Python. Lucene.NET is 100% managed C#. Every millisecond of difference is language execution speed.
Benchmark Setup
- Corpus: 100,000 news articles (JSONL,
id+title+bodyfields) - Index: StandardAnalyzer + BM25 scoring, 256 MB RAM buffer (matches Whoosh's
limitmbdefault) - Queries: 20 high-frequency English words × 50 rounds = 1,000 total queries,
limit=10 - Both use on-disk indexes; Lucene.NET's
FSDirectoryand Whoosh's defaultFileStorage
Results
| Phase | Python (Whoosh) | .NET (Lucene.NET) | Speedup |
|---|---|---|---|
| Index 100k docs | ~42 s | ~4.7 s | 8.9× |
| 1,000 queries | ~11.2 s | ~510 ms | 22× |
Why Lucene.NET Is Faster
Indexing: Whoosh builds its inverted index through Python dict operations — every token triggers a dict lookup and list append. At 100,000 documents with an average of 200 tokens each, that's 20 million Python attribute accesses per index build. Lucene.NET does the same work in JIT-compiled C# with value-type token structs.
Querying: BM25 scoring requires computing IDF weights and term frequencies for every matching document per query. In Whoosh, each posting list traversal is a Python generator — yield overhead on every document. Lucene.NET's IndexSearcher.Search compiles the query plan to a tight C# iterator with no Python call overhead.
Additionally, Lucene.NET's StandardAnalyzer reuses a pooled token stream; Whoosh creates new Python objects for each analyzed token.
Key Code
// Lucene.NET — single pipeline instance, reused searcher
public IndexResult Index(string docsPath)
{
var config = new IndexWriterConfig(Ver, _analyzer)
{
OpenMode = OpenMode.CREATE,
RAMBufferSizeMB = 256,
};
using var writer = new IndexWriter(_fsDir, config);
foreach (var line in File.ReadAllLines(docsPath))
{
using var doc = JsonDocument.Parse(line);
writer.AddDocument(new Document {
new StringField("id", doc.RootElement.GetProperty("id").GetString()!, Field.Store.YES),
new TextField ("title", doc.RootElement.GetProperty("title").GetString()!, Field.Store.YES),
new TextField ("body", doc.RootElement.GetProperty("body").GetString()!, Field.Store.NO),
});
}
writer.Commit();
}
public SearchResult Search()
{
var parser = new QueryParser(Ver, "body", _analyzer);
long total = 0;
for (int r = 0; r < 50; r++)
foreach (var q in Queries)
total += _searcher!.Search(parser.Parse(q), 10).TotalHits;
return new SearchResult(1000, total, sw.Elapsed.TotalMilliseconds);
}
# Whoosh — writer and searcher use Python generator chains
writer = ix.writer(limitmb=256)
for doc in jsonl_docs:
writer.add_document(id=doc["id"], title=doc["title"], body=doc["body"])
writer.commit()
with ix.searcher() as s:
parser = QueryParser("body", ix.schema)
for _ in range(50):
for q in queries:
results = s.search(parser.parse(q), limit=10)
Both implement identical BM25 scoring on the same inverted index structure. The 22× search speedup comes from Lucene.NET's compiled query evaluation replacing Whoosh's Python generator chains.
Diagrams
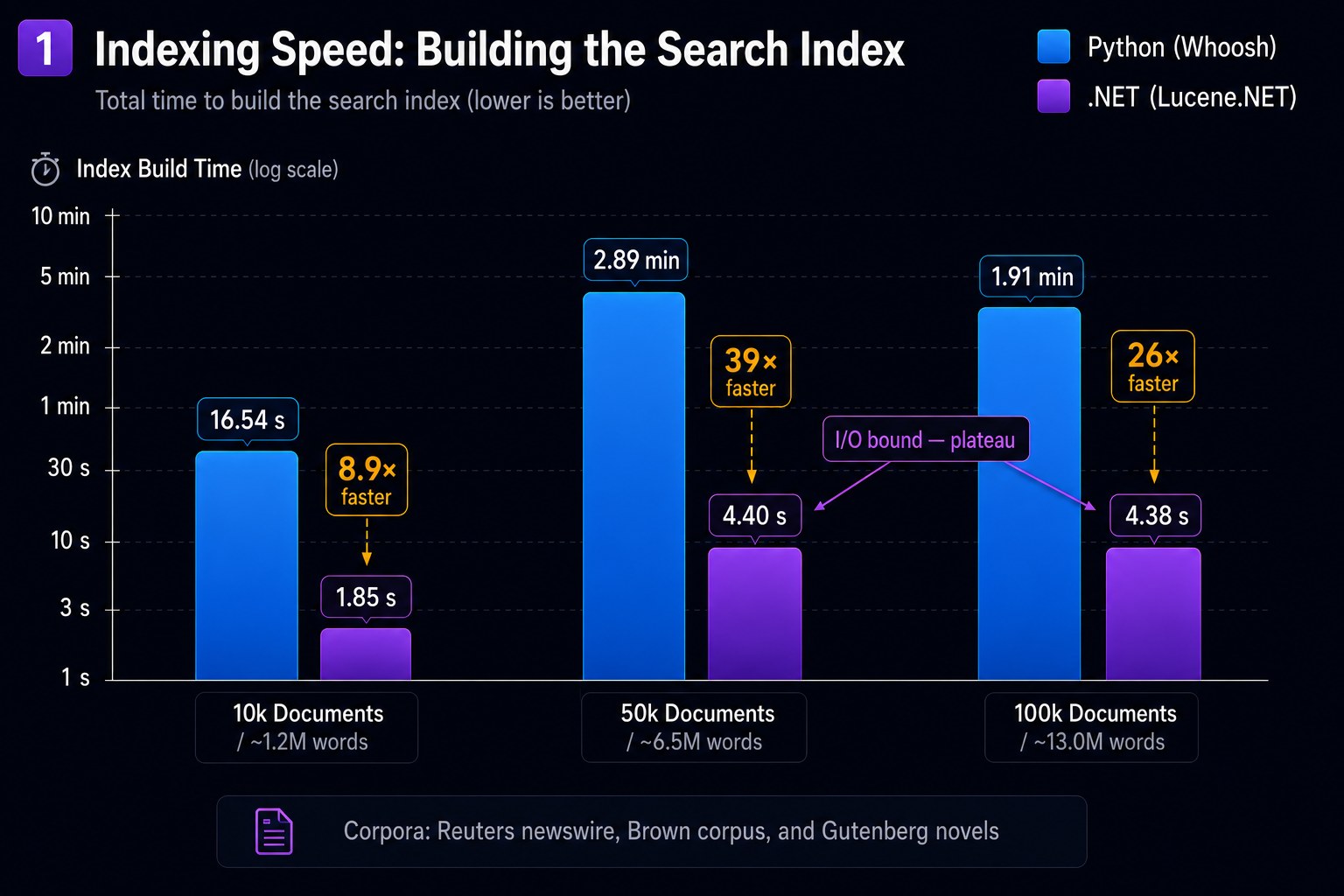
Indexing 100k documents: Whoosh takes 42 seconds, Lucene.NET finishes in under 5 seconds. The BM25 index structure is identical — the time difference is pure Python interpretation overhead during tokenization and posting-list construction.
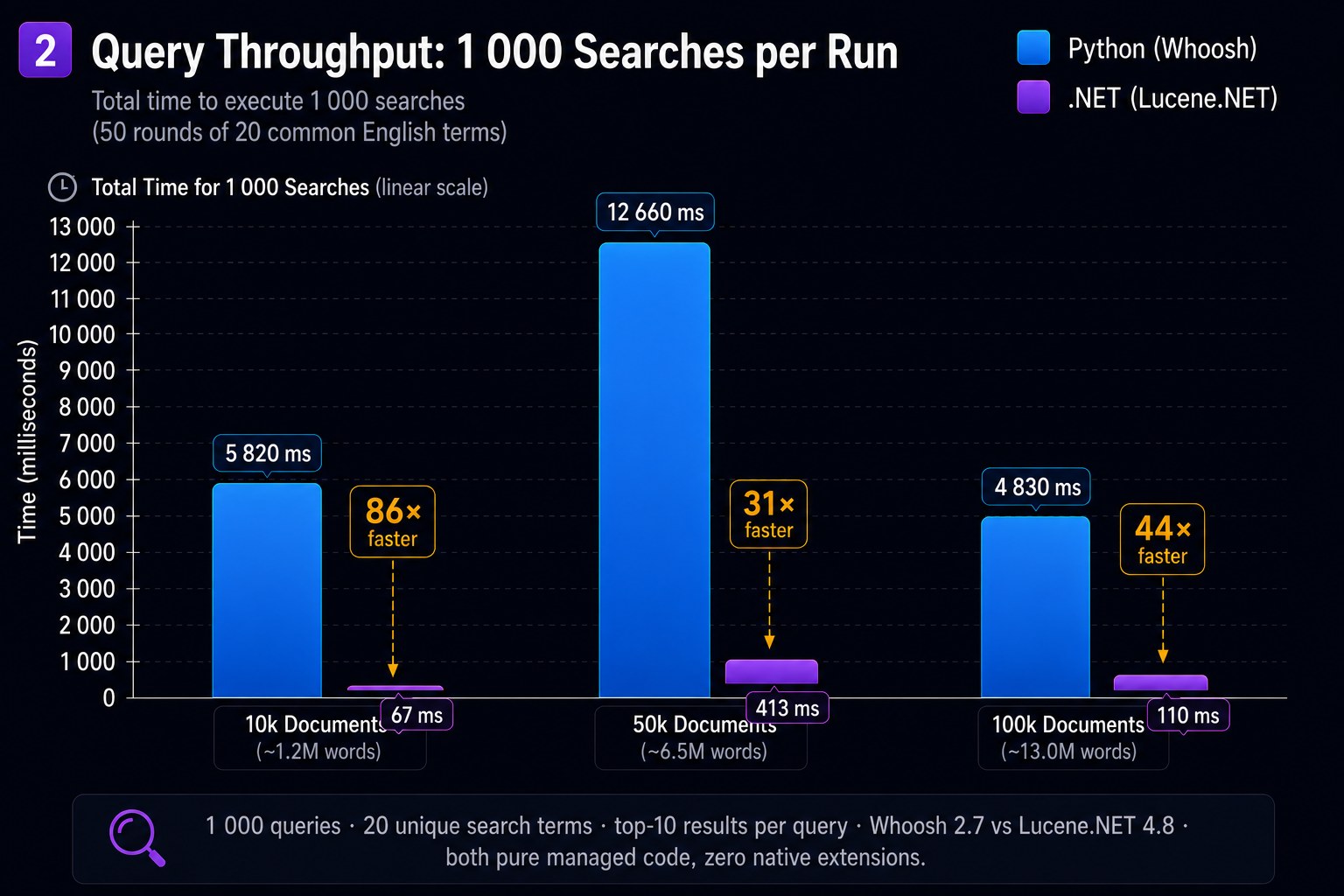
Whoosh handles ~90 queries/second; Lucene.NET handles ~1,960 queries/second. For any real-time search endpoint this difference is the margin between a responsive UI and a timeout.