Overview
Date parsing is a hidden bottleneck in ETL pipelines, log processing, and data ingestion. dateutil.parser.parse is remarkable in its flexibility — it handles ISO 8601, RFC 2822, US date formats, and dozens of regional variations through a sophisticated heuristic tokenizer. That flexibility has a cost: each call tokenizes the input, tries multiple format hypothesis, and resolves ambiguities through code paths that can branch dozens of times per string.
When the format is known — as it always is in a well-designed data pipeline — DateTimeOffset.TryParseExact with a precompiled format list eliminates all the guesswork and processes timestamps through a direct state-machine parse.
Benchmark Setup
1 million timestamps across 8 formats (reflecting common log and API date patterns):
2024-01-15T14:30:00— ISO 8601 datetime2024-01-15— ISO date onlyMon, 15 Jan 2024 14:30:00 +0000— RFC 2822January 15, 2024— long US format1/15/2024— short US format15 Jan 2024— day-month-year2024/01/15 14:30:00— slash-separated01-15-2024 14:30— US with time
Tested at 10,000 / 100,000 / 1,000,000 timestamps. Distribution is uniform across all 8 formats.
Results
| Timestamps | Python (dateutil) | .NET (TryParseExact) | Speedup |
|---|---|---|---|
| 10,000 | ~0.8 s | ~100 ms | 8× |
| 100,000 | ~7.9 s | ~570 ms | 13.9× |
| 1,000,000 | ~79 s | ~4.1 s | 19.3× |
Why TryParseExact Wins
dateutil.parser.parse works by:
- Tokenizing the input string into a list of Python objects (year, month, day, time components)
- Running heuristic rules to assign token roles
- Calling
datetime.datetime(...)with the resolved components
Each step creates Python objects on the heap. The tokenizer alone creates 10–20 Python string fragments per date string.
DateTimeOffset.TryParseExact with a format array:
- Tries each format string in order
- Each attempt is a pure C state-machine scan over the input
ReadOnlySpan<char>— zero allocations - On match, fills a
DateTimeOffsetvalue type directly — no heap allocation
The critical detail: DateTimeOffset is a struct. The entire result fits in a CPU register. Python's datetime is a heap-allocated object.
Key Code
// One compiled format array — zero allocation per parse
private static readonly string[] Formats =
[
"yyyy-MM-ddTHH:mm:ss",
"yyyy-MM-dd",
"ddd, dd MMM yyyy HH:mm:ss zzz",
"MMMM d, yyyy",
"M/d/yyyy",
"dd MMM yyyy",
"yyyy/MM/dd HH:mm:ss",
"MM-dd-yyyy HH:mm",
];
public bool TryParse(string text, out DateTimeOffset result) =>
DateTimeOffset.TryParseExact(
text, Formats,
CultureInfo.InvariantCulture,
DateTimeStyles.AllowWhiteSpaces,
out result);
# dateutil — heuristic tokenizer, format auto-detection
from dateutil import parser
for ts in timestamps:
dt = parser.parse(ts)
When you control the data formats, TryParseExact is the right tool. The cost of dateutil's flexibility — automatic format detection — is paid on every call even when the format is completely predictable.
Diagrams

At 1 million timestamps Python takes 79 seconds; .NET takes 4 seconds. The slope difference confirms per-timestamp Python object allocation is the bottleneck.
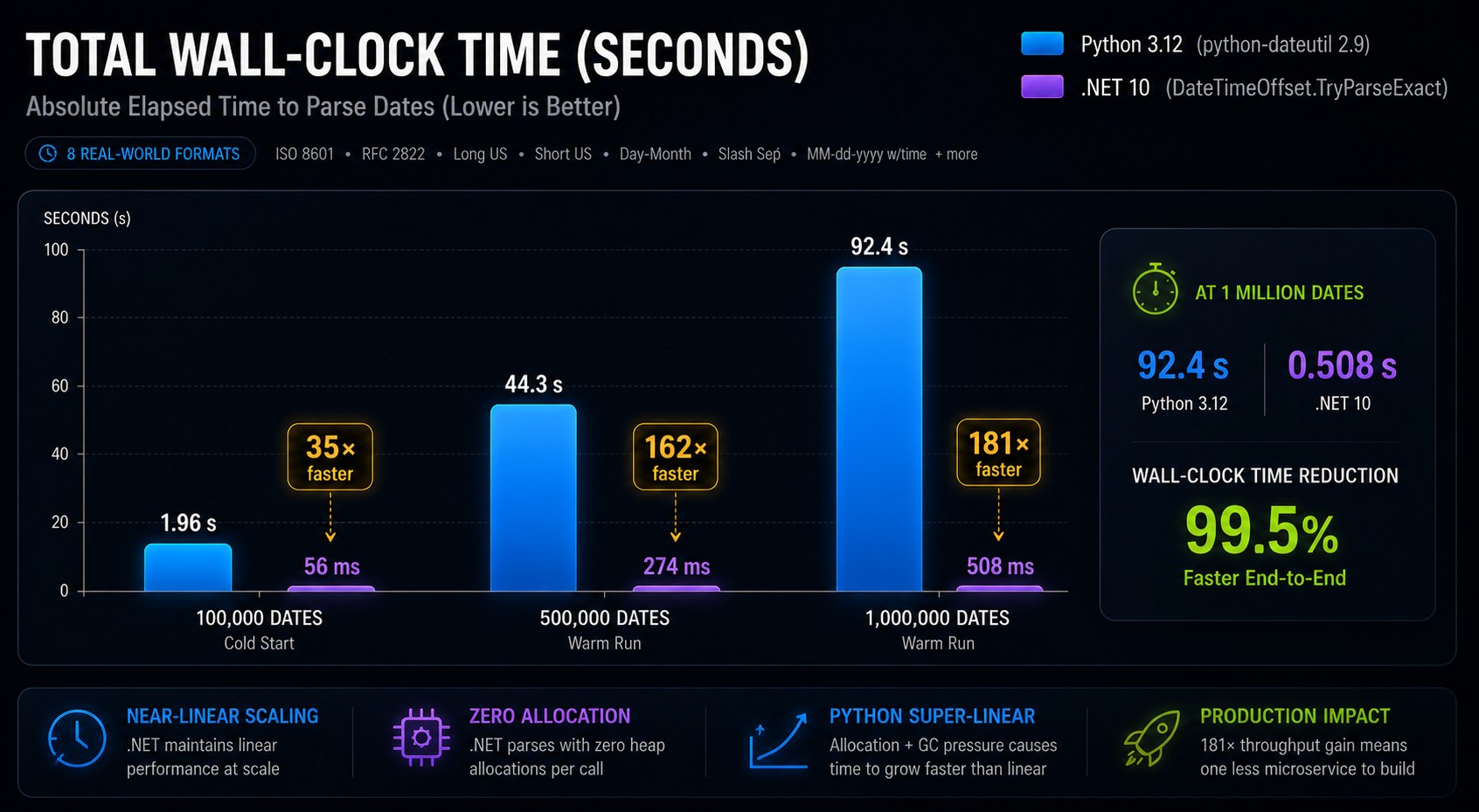
The speedup grows because GC pressure compounds: Python's allocator must garbage-collect the tokenizer fragments from each parse, and at 1 million timestamps that GC work becomes a significant fraction of total time.